
[ad_1]
MemVerge, a supplier of software program designed to speed up and optimize data-intensive purposes, has partnered with Micron to spice up the efficiency of LLMs utilizing Compute Categorical Hyperlink (CXL) know-how.
The corporate’s Reminiscence Machine software program makes use of CXL to cut back idle time in GPUs attributable to reminiscence loading.
The know-how was demonstrated at Micron’s sales space at Nvidia GTC 2024 and Charles Fan, CEO and Co-founder of MemVerge stated, “Scaling LLM efficiency cost-effectively means protecting the GPUs fed with knowledge. Our demo at GTC demonstrates that swimming pools of tiered reminiscence not solely drive efficiency greater but additionally maximize the utilization of treasured GPU assets.”
Spectacular outcomes
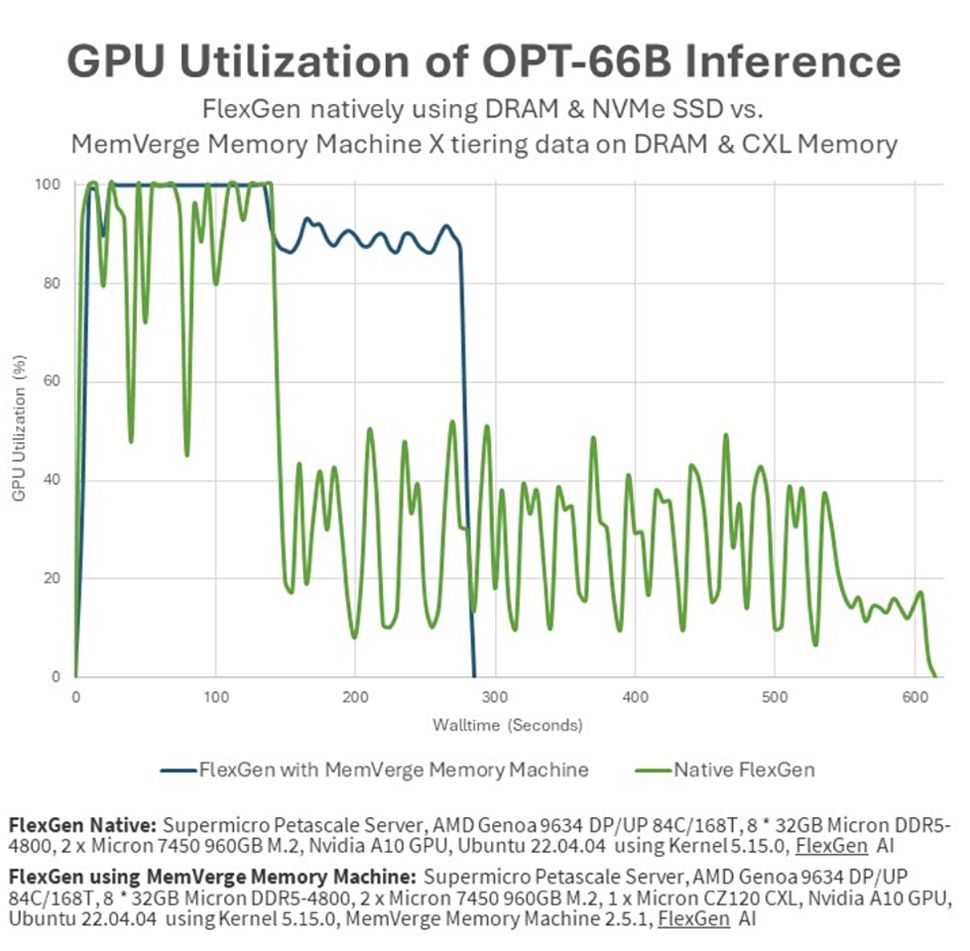
The demo utilized a high-throughput FlexGen era engine and an OPT-66B giant language mannequin. This was carried out on a Supermicro Petascale Server, geared up with an AMD Genoa CPU, Nvidia A10 GPU, Micron DDR5-4800 DIMMs, CZ120 CXL reminiscence modules, and MemVerge Reminiscence Machine X clever tiering software program.
The demo contrasted the efficiency of a job working on an A10 GPU with 24GB of GDDR6 reminiscence, and knowledge fed from 8x 32GB Micron DRAM, in opposition to the identical job working on the Supermicro server fitted with Micron CZ120 CXL 24GB reminiscence expander and the MemVerge software program.
The FlexGen benchmark, utilizing tiered reminiscence, accomplished duties in below half the time of conventional NVMe storage strategies. Moreover, GPU utilization jumped from 51.8% to 91.8%, reportedly on account of MemVerge Reminiscence Machine X software program’s clear knowledge tiering throughout GPU, CPU, and CXL reminiscence.
Raj Narasimhan, senior vp and common supervisor of Micron’s Compute and Networking Enterprise Unit, stated “By means of our collaboration with MemVerge, Micron is ready to reveal the substantial advantages of CXL reminiscence modules to enhance efficient GPU throughput for AI purposes leading to quicker time to insights for patrons. Micron’s improvements throughout the reminiscence portfolio present compute with the required reminiscence capability and bandwidth to scale AI use instances from cloud to the sting.”
Nevertheless, specialists stay skeptical in regards to the claims. Blocks and Recordsdata identified that the Nvidia A10 GPU makes use of GDDR6 reminiscence, which isn’t HBM. A MemVerge spokesperson responded so far, and others that the positioning raised, stating, “Our answer does have the identical impact on the opposite GPUs with HBM. Between Flexgen’s reminiscence offloading capabilities and Reminiscence Machine X’s reminiscence tiering capabilities, the answer is managing all the reminiscence hierarchy that features GPU, CPU and CXL reminiscence modules.”
Extra from TechRadar Professional
[ad_2]
Source link

![[Agenda] Environment, Ukraine imports, fish and Easter this WEEK](https://thepublic.app/wp-content/uploads/https://media.euobserver.com/440ec3b6fa7a076f46986df8290ee230-800x.jpg)
